")
by Isaac Zarspada
Earlier this month, one of evolv’s clients came to us with a challenge: They had a labor-intensive, 80-hour manual process for analyzing commercial financial documents and assessing a company’s credit worthiness.
The output of this process was a document called a Credit Authorization Memorandum, or CAM.
What makes generating a CAM challenging is that it is typically 50–60 pages long, must contain accurate and unbiased information, and draws on highly variable input sources. These inputs can range from 100+ page financial statements and income statements to Excel worksheets to market research papers. Bringing all of this together into a single coherent, decision-ready document is a heavy manual burden.
The question was simple: Could we automate it?
Technological Approach
We began by experimenting with Hugging Face Transformers. We built a Python pipeline to process the PDF’s documents, created a fast API backend and a frontend using HTML + CSS. We also implemented JSON Extraction and Jinja2HTML templates. To avoid redundant processing, we logged each document with fingerprints using sha256.
At this stage, everything ran locally. But as we onboarded larger sets of documents and ran repeated tests, we quickly hit bottlenecks: processing times grew, collaboration was limited to a single machine, and managing different model variants became cumbersome. These pain points made it clear we needed both scale and flexibility to handle enterprise use cases.
Moving to Snowflake: A/B Testing for Speed and Development
When we ran an A/B test comparing local development time and processing speed versus Snowflake, the results were clear:
- Snowflake gave 2x faster processing with XS Warehouse vs local i7 CPU;
- Snowflake allowed us to optionally integrate Hugging Face transformers in the background for more complex cases;
- Out of the box, Snowflake Cortex gave us powerful functionality: parse_text, extract_text, summarize, and complete, along with access to the latest models (such as Mistral, Llama 3, and GPT-style models) without needing additional setup;
- Snowflake also offered built-in Git Workspaces for CI/CD and collaboration.
This hybrid setup gave us the best of both worlds: the simplicity of Snowflake with the flexibility of open-source models.
Document Categorization Before Assembly
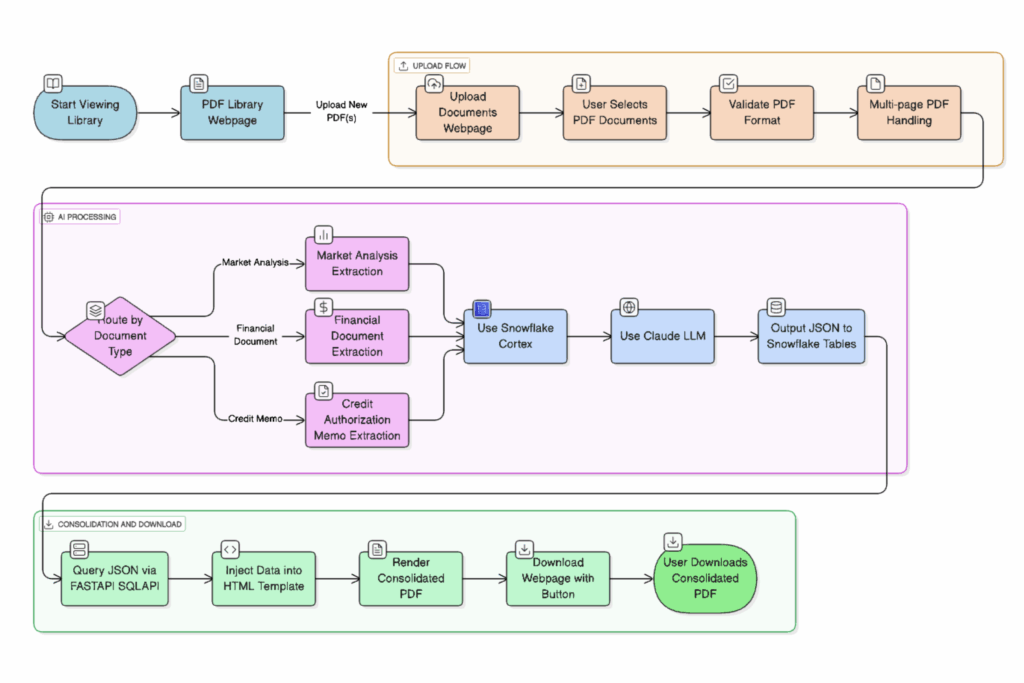
Before assembling the CAM documents, we first had to categorize the types of PDFs being ingested. Not every document contained the same type of information, and the correct processing model and prompt depended heavily on the category. We defined three high-level classes:
- Financial PDFs: Containing balance sheets, income statements, and other financial records
- Market PDFs: Containing demographic, risks, or competitor analysis
- Other PDFs: Miscellaneous supporting documents that required lighter extraction
To achieve this, we combined Python filename mapping (file name conventions and metadata) with Snowflake context search across document content. By searching for specific keywords inside the extracted text (e.g., “balance sheet,” “income statement,” “CAGR”), we could reliably deduce the document category. This categorization step then dictated which Snowflake Cortex model and prompt template we would apply in the next phase.
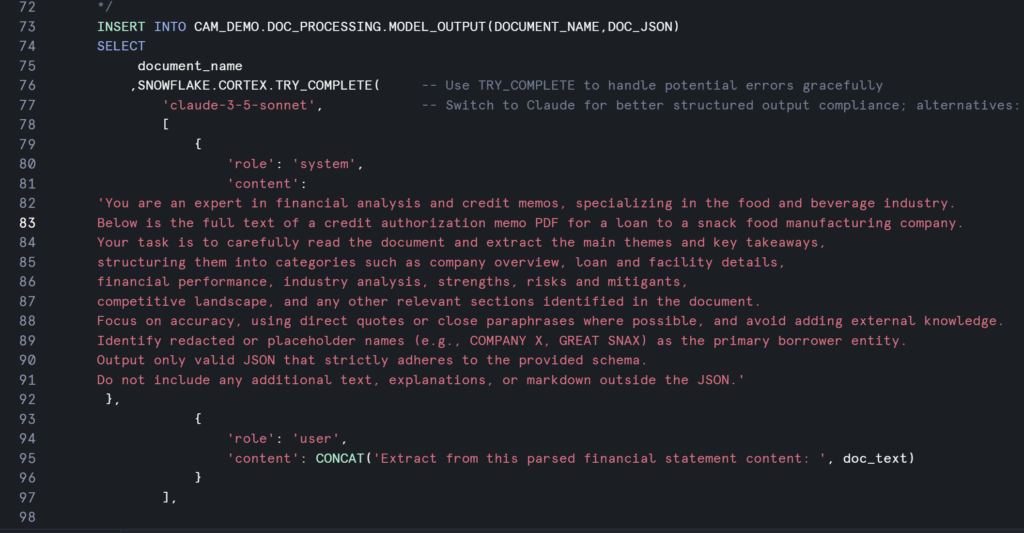
Document Assembly with Jinja2 + Snowflake Cortex
The real magic happened when we tied the process together.
- Extracting text from PDFs → We used parse_text and extract_text to load the content into Snowflake tables.
- Asking questions of the text → With Snowflake Cortex Complete, we could query the markdown directly and generate structured answers.
- Summarizing into JSON → Using Snowflake Cortex Summarize, we converted markdown into JSON models.
- Injecting into HTML templates → We used Jinja2HTML to map JSON parameters into a pre-formed CAM document template.
The result? A fully assembled CAM document in HTML, ready to be loaded into the front end.
Results and Next Steps
In the end, we transformed an 80-hour manual workflow into a 15-minute automated pipeline that:
- Reads and processes PDFs;
- Extracts structured insights from Qualitative + Quantitative information;
- Generates a ready-to-use CAM document.
This not only introduced 10x time savings but also made the process repeatable, scalable, and audit-friendly.
Are you looking to simplify one of your organization’s manual processes to save time and money? Contact evolv to get started.

Isaac Zarspada is a versatile Data & AI professional and consultant at evolv, recognized for delivering innovation and measurable impact. With deep expertise in Snowflake (Snowflake Certified), Python, cloud data platforms, and modern data engineering, Isaac empowers organizations to harness the full potential of their data through scalable, AI-driven solutions. His background spans advanced analytics, automation, and custom application development, positioning him as a trusted partner for businesses embracing digital transformation. Based in Dallas, Isaac blends technical mastery with entrepreneurial vision, consistently driving outcomes that push the boundaries of what data can achieve.


