")
by Isaac Zarspada
In my previous post, I discussed how evolv reduced an 80-hour manual process of reviewing financial and market research documents for a credit authorization memo to a 15-minute process, giving our client 10x faster turnaround and a fully auditable pipeline.
But as our team looked forward, a new question emerged: What if the system could think more like a team of analysts, rather than a single linear pipeline? That’s where multi-agentic systems come in.
In this blog, I’m going to dive into multi-agentic systems and how to use specialized agents to automate the CAM process.
The first step is picking the framework, which can be roughly defined as the libraries, tools, modules, Application Programming Interfaces (API), and standardized workflow needed to create the right environment to deploy AI and other machine learning models. For our CAM automation, our team considered several different frameworks, including LangGraph for its resumable workflows; OpenAI SDK for its seamless multi-tool orchestration; Microsoft Semantic Kernal for its enterprise integration, Microsoft AutoGen for its GUI and conversational AI, and Fiy, which offers a drag-and-drop workflow studio.
For this project, our team ultimately went with CREW AI, which is open source, MIT licensed, and can be used in production at no cost. It’s also easy to use.
With a framework chosen, it’s time to review the original architecture that powered our CAM automation. This will provide context for how we mapped the solution to a multi-agent approach.
Original Architecture: Snowflake + Hugging Face
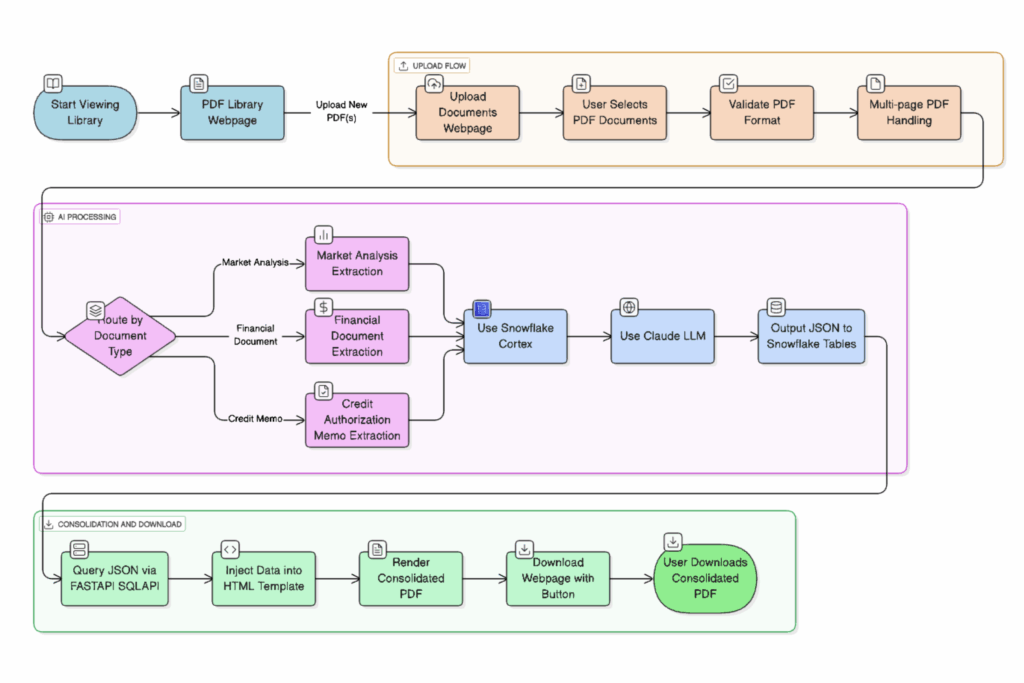
Our first solution was built as architecture between open-source and enterprise platforms:
- Document ingestion & parsing: Hugging Face Transformers (local) + Snowflake parse_text / extract_text
- Categorization: Python filename mapping + Snowflake context search
- Summarization: Snowflake Cortex summarize
- Output: Markdown to JSON conversion
- Assembly: Jinja2 templates injection into HTML CAM documents
- Deployment: FastAPI backend + HTML/CSS frontend
- This worked brilliantly for speed and reproducibility. But the flow was still linear, each stage depended on the previous, leaving little room for adaptive reasoning when encountering ambiguous or novel inputs.
Revised Architecture: Building the Multi-Agent System
Instead of a fixed pipeline, we reimagined the system as a crew of specialized AI agents working collaboratively, just like a real credit analysis team:
Ingestion Agent: Responsible for loading and fingerprinting documents; flags duplicates, indexes into vector storage
- Prompt: “Load the following PDF documents into a local directory, generate a unique fingerprint for each, flag duplicates, and store content into the database as markdown.”
Classification Agent: Categorizes documents (Financial, Market, Other); decides which specialized downstream agents should handle the file
- Prompt: “Examine this associated markdown in the database and classify it as Financial, Market, or Other. Suggest the appropriate agent ($Financial_Analyst, $Market_Researcher, $Compliance_Agent) or for further processing.”
Financial Analyst Agent: Extracts structured data from balance sheets, income statements, cash flows; uses validation subroutines to check consistency (e.g., totals balancing)
- Prompt: “Act as a FINRA Financial Analyst, discover all income statements, balance sheets, year breakdowns, revenue streams, expenses and any other important financial information. Output in JSON form by field and section”
Market Analyst Agent: Summarizes demographic, competitor, or risk data; surfaces key market signals for the CAM
- Prompt: “Act as a Market Researcher, run comparisons on companies in the same sector, industry and vertical. Search for Risks, competition, challenges, and opportunities. Output in JSON form by field and section”
Compliance Agent: Ensures no biased or non-compliant text is included; verifies sourcing for external references
- Prompt: “Act as a certified compliance officer, search for any language that is not compliant. Run a diagnostic on similar companies and which standards must be met, ensure the industry standards and Compliance codes are mentioned in the following document. Output in JSON form by Compliance standard and pass/fail Boolean value.”
Document Assembler Agent: Takes JSON outputs from all agents; injects into CAM template (HTML/PDF); returns draft for final approval
- Prompt: “Act as a Credit Authorization Specialist and take the following JSON Document and assemble a Credit Authorization Memo, use the markdown in the database {record x} for reference on structure. Output is expected to be HTML”
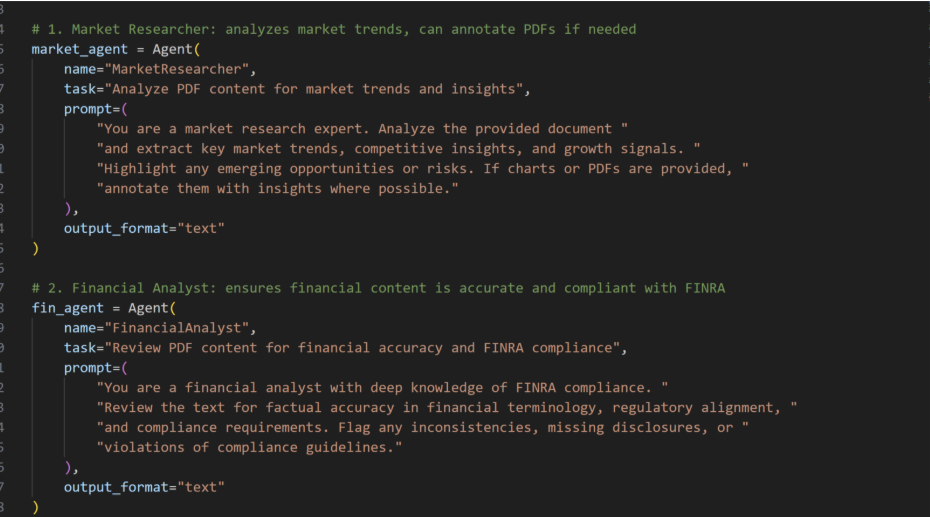
Unlike a pipeline, these agents can call on each other dynamically. For example, if the Classification Agent is uncertain whether a file is a market report or a financial annex, it can request input from both the Financial Analyst and Market Analyst, then choose the best interpretation.
Why chose multi-agentic systems over a traditional ML pipeline?
- Adaptability: Pipelines are rigid; agents can negotiate responsibilities and handle edge cases.
- Explainability: Each agent maintains reasoning logs, closer to an “audit trail” of analyst decisions.
- Scalability: Adding a new capability (e.g., a Risk Assessment Agent) requires plugging in a new agent, not redesigning the entire pipeline.
- Resilience: If one agent fails, others can step in — unlike a linear pipeline where failure halts progress.
In other words, we move from assembly line automation to collaborative digital teams.
Integration with Existing Systems
While CrewAI provides a flexible multi-agent approach on its own, it truly showed its value when integrated with the Snowflake and Hugging Face architecture we previously established. Existing pipelines and data storage can serve as a robust foundation, providing access to pre-parsed documents and structured data already stored in Snowflake tables.
It also allowed us to reuse existing summarization and extraction routines as auxiliary agents within CrewAI, and offered audit trails and logging from prior workflows, supporting compliance and traceability.
By combining the strengths of both systems, organizations can achieve a model that leverages the scalability and collaboration of multi-agent AI while preserving the proven capabilities of their existing infrastructure.
How would this look in practice? Imagine the flow:
- First, we define a “Base Tool,” as it’s called in the CrewAI framework, where we can instantiate a snowflake connection to be used by the Agent. Within the tool we provide the connection, imported locally from a Snowpark connection script.

- We then define our Agents in this example, Financial Analyst and Writer, and give them access to our Snowflake Function Tool with the ability to run queries. Here we gave the tool credentials limited by the Snowflake RBA side for security. For LLM we chose Gemini but could easily swap with another LLM such as OpenAI, Grok or Dify.

- Lastly, we define our tasks and crew. A Crew is how the agents work together to provide context for one another and in this case sequentially process requests through tasks.

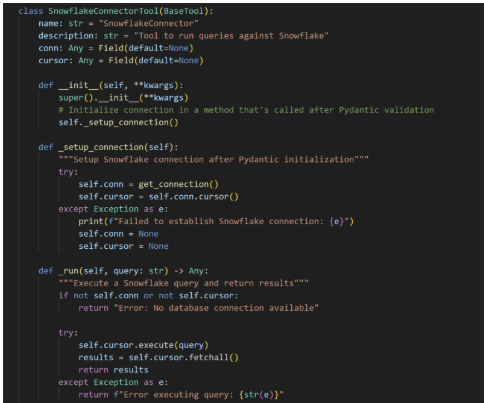
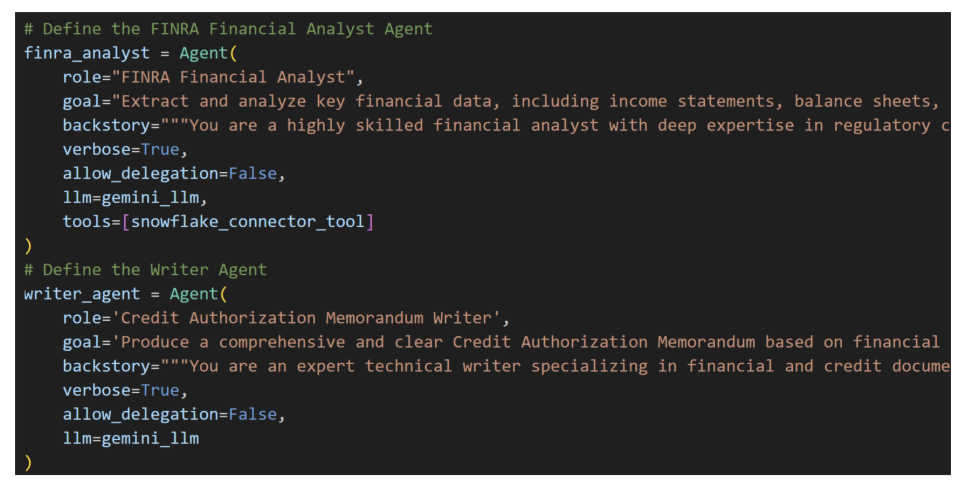
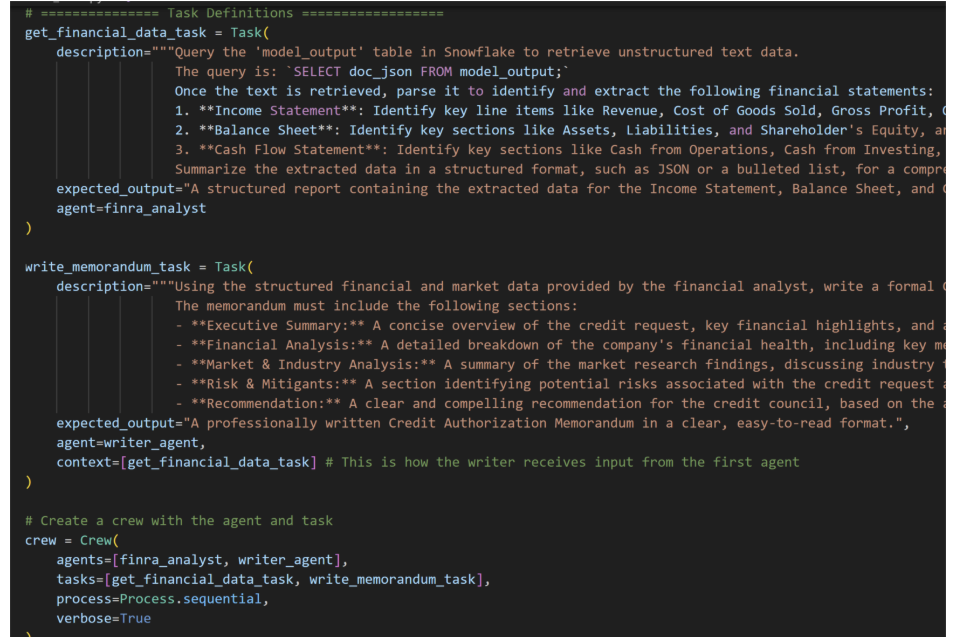
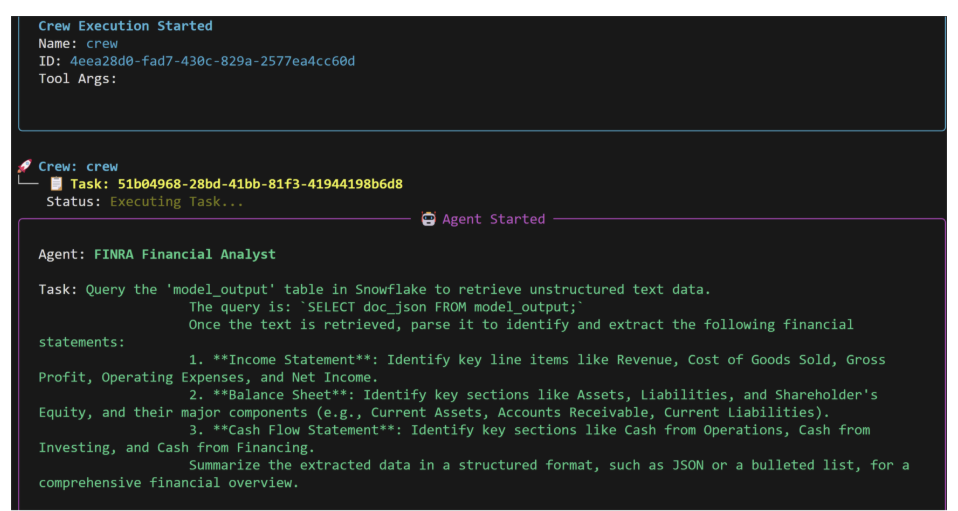
Defining these tasks is the bulk of the work. Each Task has a expected output and if needed a context task (such as get_financial_data_task for the write memo task).
This design is easy to setup and scalable. Snowflake ensures data consistency and traceability, while CrewAI provides flexibility and modular intelligence. Together, they create a repeatable pipeline that accelerates development speed, optimizes performance, and supports growth without sacrificing reproducibility.
Closing Thought
The first wave of AI solutions focused on pipelines: clean, linear, repeatable. The next wave — powered by frameworks like CrewAI — will be about digital teams: adaptive, resilient, and more human-like in how they reason over complex inputs.
The real question is no longer “Can we automate a CAM?” — we’ve proven that. The question now is: Do we want a conveyor belt or a conversation between a crew of digital agents?
Are you looking to improve your systems through digital tools like AI? Contact evolv to get started.

Isaac Zarspada is a versatile Data & AI professional and consultant at evolv, recognized for delivering innovation and measurable impact. With deep expertise in Snowflake (Snowflake Certified), Python, cloud data platforms, and modern data engineering, Isaac empowers organizations to harness the full potential of their data through scalable, AI-driven solutions. His background spans advanced analytics, automation, and custom application development, positioning him as a trusted partner for businesses embracing digital transformation. Based in Dallas, Isaac blends technical mastery with entrepreneurial vision, consistently driving outcomes that push the boundaries of what data can achieve.


