 (1)")
by Chris Schneider
Snowflake Dynamic Tables enable fresh, transformed data without the complexity of traditional pipeline management. Scheduling, dependency tracking, and even source CDC are handled automatically by Snowflake, freeing data teams to focus on what matters most.
Originally released in April 2024, Dynamic Tables brought native pipeline capabilities to Snowflake, making data transformation easier, more flexible, and more intelligent. Key features included United Batch and Streaming Workflows, which support hybrid pipelines and offer processing in near-real-time or on a scheduled basis; Declarative Pipeline Design, which uses an SQL-first, declarative approach to allow users to focus on business logic and desired outcomes; Automatic Dependency Management, which helps reduce costs, resource uses and latency by refreshing downstream tables only when upstream data changes; and Freshness Targets for Real-Time Analytics, giving users the ability to control how often their tables refresh, enabling real-time insights without the need for a dedicated streaming infrastructure.
By late 2024, Snowflake extended Dynamic Table functionality to integrate with Snowpipe Streaming, Iceberg Tables, and Native Apps, creating a more cohesive and scalable platform.
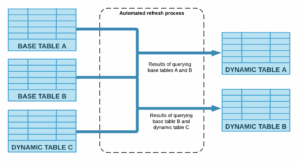
Tables, including other dynamic tables, are automatically sourced to refresh dynamic tables.
Yet despite these groundbreaking features, some data engineers still needed more control to optimize cost and accelerate time-to-insight. That’s where the latest enhancements come in, bringing greater intelligence, flexibility, and control to data pipelines.
Updates expected to come online this year include:
- Filter by Current Date or Time: Generally Available Now
This new feature will allow Snowflake users to utilize date/time relevancy filters directly in the WHERE, HAVING, or QUALIFY clauses, which will minimize processing and reduce costs.

Code snippet of the use current_timestamp to filter processing for only current records.
- Immutability: Coming Soon›
Snowflake users will soon be able to mark a region of a Dynamic Table as immutable using the IMMUTABLE WHERE (condition) clause. That means this region cannot be updated, inserted, or deleted, regardless of changes in the source. Benefits of immutability include:
- Retaining historical data, even if removed upstream;
- Enabling efficient query evolution and replication without re-initializing the table;
- Avoiding costly re-computation of unchanged result rows;
- Gaining control by refreshing only the mutable region.
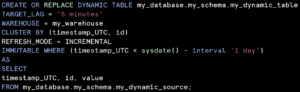
Code snippet of the use immutable region to eliminate changes to data older than one day.
- Insert-Only Inputs: Private Preview Available
With this feature, users can configure Dynamic Tables to process only inserts from the result set. Advantages include a greatly improved performance, since inserts are the least expensive operation in Snowflake; and increased flexibility, allowing users to remove records from upstream sources more frequently without affecting downstream results.
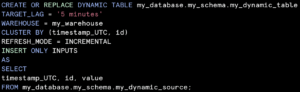
Code snippet of the use insert only to process only inserts and ignore deletes and updates.
- Backfill: Generally Available Soon
Backfill allows users to seed a Dynamic Table with existing data, leveraging immutability and Snowflake’s Zero-Copy Clone feature, which allows you to create a database clone without duplicating the underlying data. Backfill’s use cases include the ability to create a Dynamic Table from already cleaned and processed historical data and changing a table definition without reprocessing months or years of data.
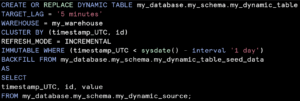
Code snippet of the use backfill option to seed the dynamic table from already processed data.
Real-World Applications
Dynamic Tables don’t just simplify pipeline automation, they unlock powerful business use cases. Retailers can track inventory and customer behavior in real-time. The finance industry can use low-latency updates to detect fraud as soon as it happens. Operations systems can function with power live dashboards that don’t require complex ETL processes.
The evolv Consulting team is ready to help you leverage Snowflake’s Dynamic Tables to generate real-time insights with greater control. Connect with our Snowflake team to learn more.
Chris Schneider helps organizations unlock the full potential of their data ecosystems by designing scalable architectures and intuitive processes that prioritize quality. With deep expertise in Data Architecture and a strong foundation in Financial Services, Chris has led transformative initiatives that turn complex data challenges into strategic advantages. His work includes building metadata-driven frameworks and robust analytic capabilities that empower teams to use the right tools effectively, driving informed decisions and measurable successes.


